









服務熱線
0755-83044319

發布時間:2022-03-17作者來源:薩科微瀏覽:2018
RISC-V 一直是計算領域最熱門的話題之一,因為這個指令集架構 (ISA) 允許進行廣泛的定制并且易于理解,此外還有整個開源、免許可的好處。甚至還有一個基于 RISC-V ISA 設計通用 GPU 的項目,現在我們正在見證英偉達的 CUDA 軟件庫移植到 Vortex RISC-V GPGPU 平臺。
Nvidia 的 CUDA(計算統一設備架構)代表了一個獨特的計算平臺和應用程序編程接口 (API),它運行在 Nvidia 的顯卡系列上。當為 CUDA 支持編寫應用程序時,只要系統發現基于 CUDA 的 GPU,它就會獲得大量的代碼 GPU 加速。
今天,研究人員研究了一種在名為 Vortex的RISC-V GPGPU 項目上啟用 CUDA 軟件工具包支持的方法。Vortex RISC-V GPGPU 旨在提供基于 RV32IMF ISA 的全系統 RISC-V GPU。這意味著 32 位內核可以從 1 核擴展到 32 核 GPU 設計。它支持 OpenCL 1.2 圖形 API,今天它還支持一些 CUDA 操作。
研究人員解釋說:“……在這個項目中,我們提出并構建了一個pipeline來支持端到端的 CUDA 遷移:pipeline接受 CUDA 源代碼作為輸入并在擴展的 RISC-V GPU 架構上執行它們。我們的pipeline包括幾個步驟:將CUDA源代碼翻譯成NVVM IR,將NVVM IR轉換成SPIR-V IR,將SPIR-V IR轉發成POCL得到RISC-V二進制文件,最后在擴展的RISC-V GPU上執行二進制文件架構。”
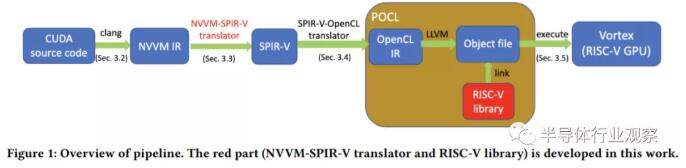
這個過程在上圖中可視化,顯示了讓它工作的所有步驟。簡單來說,CUDA 源代碼以稱為 NVVM IR 的中間表示 (IR) 格式表示,基于開源 LLVM IR。它后來被轉換為標準便攜式中間表示 (SPIR-V) IR,然后將其轉發到 OpenCL 標準的便攜式開源實現中,稱為 POCL。由于 Vortex 支持 OpenCL,因此它提供了受支持的代碼,并且可以毫無問題地執行它。
有關此復雜過程的更多詳細信息,請點擊下方閱讀原文。重要的是,您必須感謝這些研究人員為使 CUDA 能夠在 RISC-V GPGPU 上運行所做的努力。雖然這只是目前的一小步,但它可能是 RISC-V 用于加速計算應用程序時代的開始,這與 Nvidia 今天的 GPU 陣容非常相似。
延伸閱讀:RISC-V能改變GPU嗎?
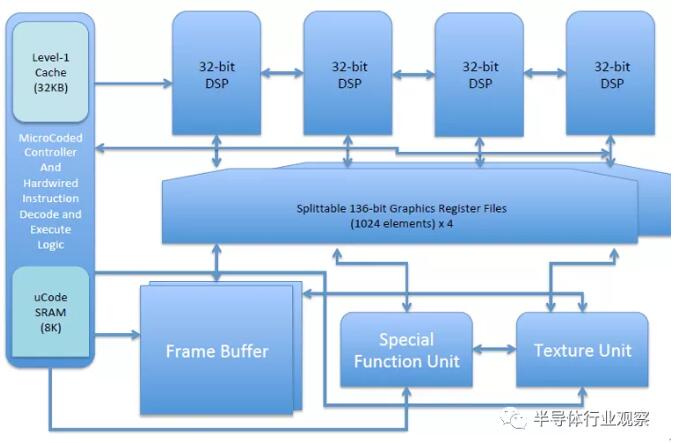
指令/數據SRAM緩存(32 kB)
微碼SRAM(8 kB)
雙功能指令解碼器(實現RV32V和X的硬連線;用于自定義ISA的微編碼指令解碼器)
四向量ALU(32位/ ALU-固定/浮動)
136位寄存器文件(1k個元素)
特殊功能單元
紋理單位
可配置的本地幀緩沖區
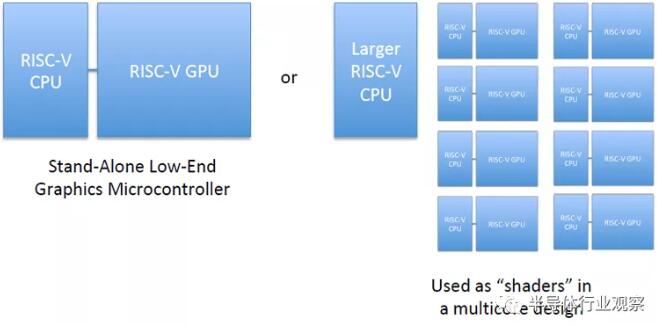
RV64X規范仍在早期開發中,可能會發生變化。正在建立一個討論論壇。近期目標是使用指令集模擬器構建示例實現。這將在使用開放源代碼IP和設計為開放源代碼項目的自定義IP的FPGA實現上運行。
免責聲明:本文轉載自“半導體行業觀察”,本文僅代表作者個人觀點,不代表薩科微及行業觀點,只為轉載與分享,支持保護知識產權,轉載請注明原出處及作者,如有侵權請聯系我們刪除。
公司電話:+86-0755-83044319
傳真/FAX:+86-0755-83975897
郵箱:1615456225@qq.com
QQ:3518641314 李經理
QQ:332496225 丘經理
地址:深圳市龍華新區民治大道1079號展滔科技大廈C座809室
友情鏈接:站點地圖 薩科微官方微博 立創商城-薩科微專賣 金航標官網 金航標英文站
Copyright ?2015-2024 深圳薩科微半導體有限公司 版權所有 粵ICP備20017602號-1
