









服務熱線
0755-83044319

發布時間:2022-09-07作者來源:薩科微瀏覽:2230
近期,清華大學集成電路學院錢鶴、吳華強教授課題組聯合斯坦福大學、加州大學圣地亞哥分校(UCSD)、圣母大學等在《自然》(Nature)發表了題為“A compute-in-memory chip based on resistive random-access memory”的研究論文,報道了一款基于憶阻器(阻變存儲器)的存算一體芯片NeuRRAM。該芯片具有可重新配置的計算核心(reconfiguring CIM cores),可以兼容不同的模型結構,與之前[敏感詞]的憶阻器存算一體芯片相比,能效提升兩倍,在多種人工智能任務中的推理準確率與四位量化權重的軟件模型結果相當。
在邊緣設備上實現復雜的人工智能應用要求硬件具有很高的能量效率,基于憶阻器的存算一體(Compute-In-Memory , CIM)系統可以將模型權重存儲在憶阻器陣列中,通過在器件內進行計算,顯著降低數據搬運帶來的能耗。[敏感詞]的研究已經證明在全集成憶阻器存算一體系統上實現矩陣向量乘法的可行性,然而現有的硬件設計無法同時滿足高能效、高通用性、高準確率的應用需求,并且這三個特性需要在不同的抽象層次協同優化。因此,如何設計一個具有高能效比、支持不同網絡結構、準確率與軟件結果相媲美的硬件系統成為憶阻器存算一體芯片在實際場景中應用的關鍵。
針對這一技術難點,研究團隊對芯片算法、系統、架構、電路與器件進行了全層次協同優化設計:器件層面,實現300萬個具有高模擬可編程性的憶阻器與CMOS電路的單片集成;電路層面,提出電壓模神經元電路,支持可變精度計算、激活操作、低功耗模數轉換;架構層面,提出雙向TNSA(transposable neurosynaptic array)架構,以最小的面積、能耗開銷實現靈活的數據流重構;系統層面,48個CIM核心支持多種權重映射方案,提高推理任務并行度;算法層面,利用多種硬件-算法協同優化方案,降低硬件非理想特性對準確率的影響。
可重構的憶阻器存算一體架構
在不同的網絡模型中,數據流的模式有所不同。例如,卷積神經網絡(convolutional neural network, CNN)中的數據在網絡層之間單向流動,長短期記憶網絡(long short-term memory, LSTM)所處理的時間數據需要在不同的時間步循環通過同一網絡層,概率圖模型(probabilistic graphical model)中概率采樣在網絡層之間往復進行。團隊提出了一種TNSA架構,包含負責模擬計算的憶阻器陣列和負責模數轉換與激活的CMOS神經元電路,二者組成交錯核心(interleaved corelet)。CMOS神經元與憶阻器陣列交叉排布,通過具有開關控制的共享位線(bit-line, BL)、字線(word-line, WL)在行、列方向互聯,在節約面積、能耗的同時,實現了數據流的靈活控制。通過合理選擇權重映射方案,充分利用48個核心的數據并行和模型并行,可以將推理任務的吞吐率[敏感詞]化。
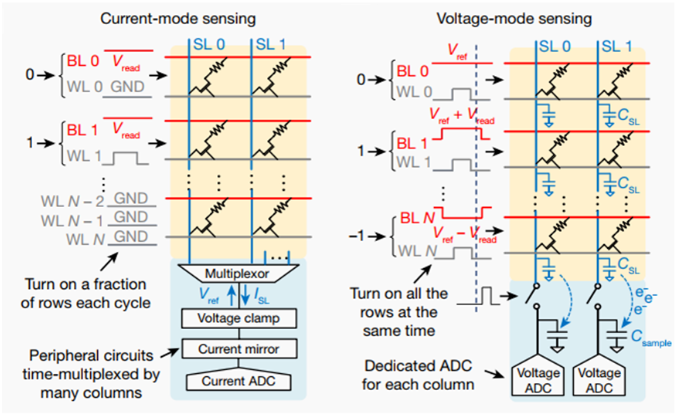
高效的電壓模神經元電路
傳統的憶阻器陣列通常采用電流模方案:基于歐姆定律,輸入為電壓值,計算結果通過輸出電流體現。然而,同時開啟多行器件會導致過大的陣列電流,從而限制“列并行性”;調整ADC以適應輸出的動態范圍需要多個時鐘周期,從而限制“行并行性”。電壓模方案可以顯著提升計算并行度和能效比。在電壓模方案中,輸出信號線浮空,其電壓值為輸入信號線電壓的加權平均。本工作提出的神經元電路利用采樣電容存儲輸出信號線的電荷、利用積分電容實現結果累加。電壓模神經元電路有效降低外圍電路的面積和功耗,自動實現動態范圍歸一化,并通過整合模數轉換與激活功能實現緊湊設計,極大提升能量、面積效率,提高計算吞吐率。
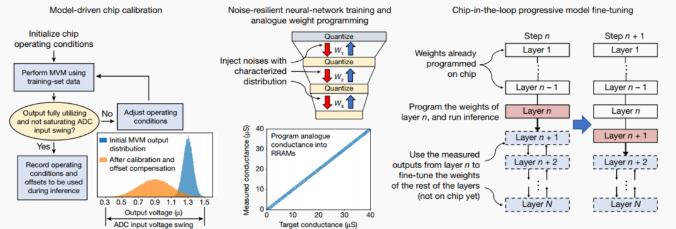
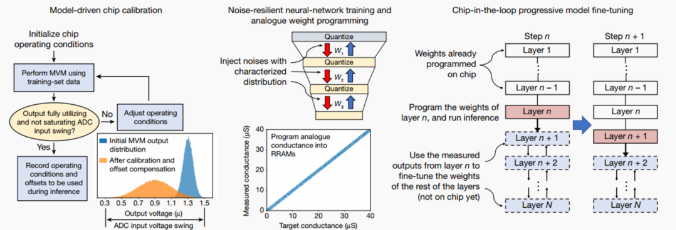
硬件-算法的協同優化方案
現有研究的實驗結果通常是在軟件中加入器件特性而仿真獲得的,在軟件仿真中忽略某些非理想特性會使預測結果過分樂觀。與之前工作不同的是,本文報道的結果均在硬件上測量獲得。硬件-算法的協同優化方案包含模型驅動芯片校準技術(model-driven chip calibration)、抗噪聲網絡訓練與模擬權重編程技術(noise-resilient neural-network training and analogue weight programming)、環漸進式模型微調技術(chip-in-the-loop progressive model fine-tuning)。模型驅動芯片校準技術利用真實的權重與輸入數據,對輸入電壓幅度、ADC偏移量等條件進行校準;抗噪聲網絡訓練與模擬權重編程技術采用添加高斯噪聲的非量化權重訓練網絡,并在憶阻器陣列中直接存儲高精度的權值,提升權重存儲密度與推理準確率;環漸進式模型微調技術通過每次僅部署一層網絡權重,并利用硬件的輸出結果,在軟件上對后續網絡層進行訓練,從而對當前編程層的非理想性進行補償。
NeuRRAM系統具有數據流可重構的TNSA架構、電壓模神經元電路、算法-硬件協同優化方案,在多個人工智能任務中實現了與軟件結果相當的推理準確率。通過在全部硬件設計層次上進行創新,NeuRRAM提高了現有憶阻器存算一體系統的能效、靈活性和準確性,其優化思路可以廣泛應用于其他非易失存儲器的設計中。隨著阻變存儲器的內存容量不斷增加,這種協同優化方案將顯著提升邊緣設備的性能、效率和通用性,讓云端任務在邊緣端的部署成為可能。
該項成果由清華大學、斯坦福大學與UCSD合作完成,清華大學集成電路學院的吳華強教授和高濱教授是本文的共同通訊作者。集成電路高精尖創新中心工程師吳大斌與清華大學集成電路學院已畢業博士生章[敏感詞]參與完成了主要電路設計、器件優化與芯片集成工藝的研究工作。清華大學錢鶴、吳華強團隊長期從事憶阻器存算一體技術的相關研究,在器件集成和芯片設計等方面取得了多項突破性進展,曾在2020年ISSCC上發表了國際[敏感詞]基于模擬型憶阻器的全系統集成存算一體芯片,并在同年《自然》期刊發表了國際[敏感詞]多憶阻器陣列的存算一體芯片,并在持續探索先進工藝下的憶阻器集成技術。
免責聲明:本文轉載自“芯系清華”,本文僅代表作者個人觀點,不代表薩科微及行業觀點,只為轉載與分享,支持保護知識產權,轉載請注明原出處及作者,如有侵權請聯系我們刪除。
友情鏈接:站點地圖 薩科微官方微博 立創商城-薩科微專賣 金航標官網 金航標英文站
Copyright ?2015-2024 深圳薩科微半導體有限公司 版權所有 粵ICP備20017602號-1
