【新智元導讀】傳統集成電路設計費時又費力,能否用人工智能來提高工作效率?在今年的集成固態電路會議上,包括Google AI負責人Jeff Dean在內的四位大佬闡述了AI的應用對處理器、量子計算、結構創新等的重大影響。「新智元急聘主筆、編輯、運營經理、客戶經理,添加HR微信(Dr-wly)或掃描文末二維碼了解詳情。」
今年的集成固態電路會議(ISSCC)的主題是“
為AI時代提供動力的集成電路”,而開幕全體會議的目的是描繪AI“折疊”半導體空間的程度。

Google AI 負責人Jeff Dean、聯發科高級副總裁Kou-Hung Loh、Imec項目總監Nadine Collaert、IBM Research總監Dario Gil分別解釋了電子領域對AI的期望要求,例如,如何驅動專門為AI應用而設計的新型處理器(以及CPU和GPU);促進結構創新(例如小芯片,多芯片封裝,中介層);甚至影響著量子計算的發展。
布局布線太費時?Google AI 幫你降本增效
ISSCC會議于上周在舊金山舉行,會議期間谷歌表示人工智能對電路設計同樣重要,并且宣布
谷歌正在嘗試利用機器學習來解決集成電路設計流程中自動化布局布線問題,并且得到了不錯的效果。
人工智能的應用這幾年來也一直是電子領域的研究熱點和重點。這個方向吸引了大量半導體研究人員從事傳統方向和人工智能結合的相關研究。尤其是今年的集成固態電路會議(ISSCC)甚至把會議主題定為:“
用集成電路推動AI新時代”。而開幕式也將此次會議的目的陳述為探討AI對半導體領域研究的影響。
開幕式的四位發言人解釋了人工智能的需求是如何推動設計AI專用的新型處理器(相比于CPU和GPU)、如何促進結構創新(例如采用小芯片,多芯片封裝,或者插件式設計)、甚至如何正在影響未來量子 計算的發展。
會議的[敏感詞]位發言人是Google AI負責人Jeff Dean。Jeff Dean提到谷歌正在通過實驗,嘗試
利用機器學習執行集成電路設計中的布局布線任務,也就是讓AI學習集成電路中的布局布線,節省設計專家的人力勞動。
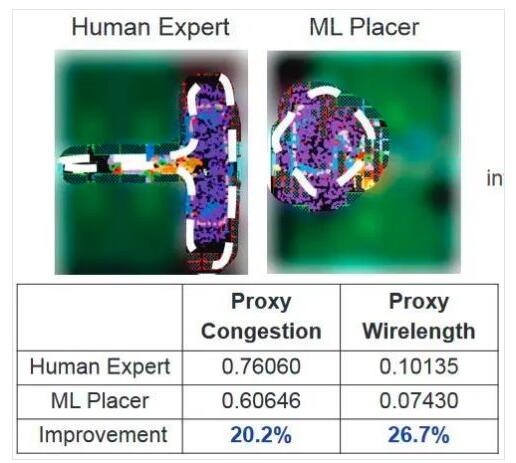
人類ASIC專家的布局布線結果和一個低功耗ML加速器芯片的布局布線結果對比。谷歌故意遮蓋了部分圖像。(來源:Google Research / ISSCC)
Jeff Dean首先簡要介紹了AI和ML的發展歷史,接著介紹了機器如何學習玩雙陸棋,深藍如何下國際象棋, alphago如何擅長下圍棋 。以及現在的AI可以應對非常復雜的視頻游戲(例如《星際爭霸》)并且取得了“具有里程碑意義的成績”。同時 機器學習還被廣泛應用于醫學成像,
機器人技術,計算機視覺,自動駕駛,神經科學,農業,天氣預報等領域。
數十年來,推動計算技術發展的基本思想是:問題越大,我們就給它更強的計算能力。如果你擁有的處理能力越強,你就可以解決的更大的問題。在一段時間里,這個規則也適用于解決AI問題。但是,這個規則很快就被爆炸式增長的問題空間所打破。因為我們根本無法攢夠足夠多的CPU/GPU來解決這樣的問題。
事實證明,
AI / ML不需要典型的CPU / GPU的復雜功能,所需的數學運算也更簡單,而且要求的精度也低很多。這個發現帶來的影響是:專用的AI / ML加速器不必像CPU / GPU那樣復雜。基于此Google設計了TensorFlow加速器,并且已經推出第三代產品,第四代產品也很快會發布。AI / ML處理器設計相對簡單,因此也相對便宜,所有這些都使得將機器學習進一步推向網絡邊緣變得更加容易。截至2019年,Google已經擁有一款可在智能手機上使用的非常緊湊的模型。
當前階段每個基于AI的應用程序(自動駕駛,醫學成像,游戲)都是通過訓練專用的AI / ML系統而實現。那么,AI能將一個系統上學到的知識應用到從未見過的新系統中嗎?答案很明確:“YES”。
“我之所以提出這一點是因為我們開始考慮將AI用于ASIC設計中的布局布線” Jeff Dean說,“
布局布線的難度遠遠大于圍棋:目標更模糊,問題規模反而更大”。Google已經創建了布局布線的學習模型,然后嘗試該工具是否可以進一步推廣。Jeff Dean說“到目前為止,我們在所有嘗試中都獲得了非常好的結果。它的性能要比人類好一些,有時甚至要好很多。”
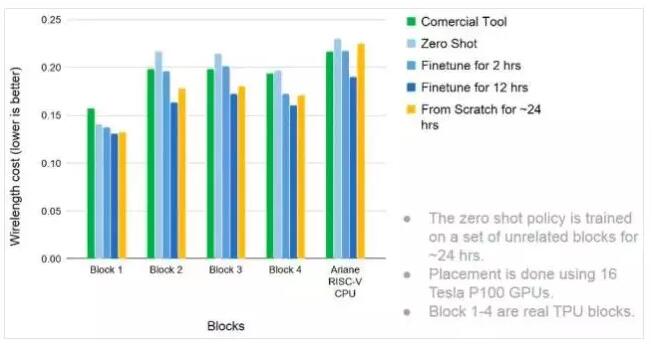
Google將使用機器學習布局和布線的效果與商用軟件進行了比較。 測試電路是幾個不同的模塊,包括Ariane RISC-V CPU。(來源:Google Research / ISSCC)
“更好”指的是在非常短的時間內完成布局布線。如果讓人類設計專家完成這項任務通常需要一周甚至數周時間。而
ML布局布線器通常在24小時內就能完成相同的工作量,并且布局的連線通常更短。ML布局布線器在自動布局和布線方面的更多出色表現可以參考由Cadence公司Rod Metcalfe撰寫的“在EDA中進行機器學習可加快設計周期”的文章。
Jeff Dean說,ML可能還會擴展到IC設計過程的其他部分,包括使用ML來幫助生成測試用例,以更充分地進行ASIC設計驗證;也許還可以使用ML來改進高級代碼綜合以達到更優化的設計。這些可能的應用方向對機器學習本身的普及很重要,同時對加速集成電路設計進度也是一樣的重要。
高成本大功耗CPU/GPU并非必須,邊緣計算可定制
聯發科技高級副總裁兼首席戰略官Kou-Hung Loh指出物聯網設備將數百億的事物連接在一起,然而AI正在改變著這些聯網的一切事物。
AI之所以走向邊緣計算,部分原因正如Dean在本節前面提到的那樣,還有更多的原因包括:
減輕數據中心日益增長的處理負擔、最小化網絡流量,以及那些需要使用近似本地處理的實時應用。本地處理要求:快速(必須為AI計算專門設計),而且低功耗。這些為AI專門設計的處理器,被稱為AI處理器單元。一個APU可以不如CPU靈活,但是由于是專用的,所以
APU可以性能上比CPU快20倍,功耗比CPU低55倍。
多系統不好協同設計?AI 幫你打通奇經八脈
Imec的項目總監Nadine Collaert指出摩爾定律可能在未來幾年內依然適用,雖然CMOS縮小的難度越來越大,但可以利用FinFETs、 納米片、forksheets等技術實現芯片級的CMOS進一步縮放。相信3D技術是[敏感詞]的方法:包括使用多層封裝,硅上穿孔,以及與其他標準單元進行精細等級的連接。具體技術的選擇需要根據系統設計需求和可選用的器件屬性來決定。“這將是一個復雜的練習”Collaert說。這將對EDA供應商產生很大壓力,因為這需要EDA供應商在工具層面支持不同方案的嘗試和比較。
無線通信系統的前端模塊將成為一個特殊的挑戰。“通常,這些系統最多樣化:使用不同技術的許多不同組件,并且前端模塊會隨著天線、PA、以及濾波器的增多,而變得更加復雜。”
無線通信行業正在向更高頻和更高效率邁進。一種方案是將III-V材料(例如GaN和SiC)與CMOS結合使用以獲得兩種材料的優勢。Nadine Collaert給出一個在絕緣的硅襯底(SOI)上生長的具有III-V材料的3D nano-ridge的圖片示例,同時指出這里還有很多工作要做。
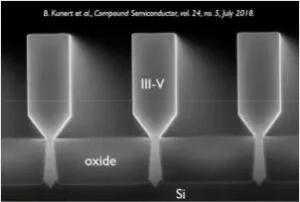
Imec證明其在絕緣硅襯底(SOI)上生長出III-V材料的3D nano-ridge的能力
至于機器學習對內存的影響則更加明顯。 像AI和ML這樣的新應用都需要快速地訪問內存。 人們迫切需要關注和發展內存計算,隨著邏輯和存儲的日益緊密,3D封裝當然會發揮重要作用。
彼此賦能,量子計算和人工智能可互補
IBM Research總監Dario Gil在會議上進一步提及廣義的AI:幾乎可以肯定,廣義的AI將會在量子計算機上實現。他總結了[敏感詞]的好處可能來自bits(數字處理),neurons(AI)和qubits(量子計算)的互補使用。IBM于2016年通過開放了[敏感詞]臺量子計算機的訪問,現在可以訪問15臺量子計算機,包括其[敏感詞]的53量子位模型。
免責聲明:本文轉載自“新智元”,本文僅代表作者個人觀點,不代表薩科微及行業觀點,只為轉載與分享,支持保護知識產權,轉載請注明原出處及作者,如有侵權請聯系我們刪除。
公司電話:+86-0755-83044319
傳真/FAX:+86-0755-83975897
郵箱:1615456225@qq.com
QQ:3518641314 李經理
QQ:332496225 丘經理
地址:深圳市龍華新區民治大道1079號展滔科技大廈C座809室











